Introduktion
Denne side beskriver de ting som man skal være opmærksom på når man bygger og arbejder med kuber.
Kort om kuben
I dit arbejde får du brug for at kende og kunne arbejde med data i “kuben” (med kuben menes primært CHRU_HRKube).
Både HR Lederdashbord og HR Strategisk Dashboard bygger på kuben. I kuben implementeres vores standardiserede beregningsmetoder indenfor temaer som sygefravær, ferieafholdelse, personalesammensætning, løn, vagtplan m.fl. Flere temaer tilføjes løbende i takt med efterspørgsel og tilgængelige datakilder, hvorfor vi altid bestræber os på, at kuben skal være en adaptiv størrelse. Hér er din indsigt i både muligheder og begrænsninger med den nuværende model værdifuld.
På produktions- og udviklingsserverne findes data under skemanavnet chru_cube. I Tabular Editor findes kuben under navnet CHRU_HRKube.
Kuben pr. 2023-01-30
Dette billede giver et overblik over tabeller inkludert i kuben. Det er ikke fyldestgørende, men giver en ide om, hvordan tabeller tilføjes temavis i takt med, at vi løbende inkluderer flere datakilder.Som introduktion til kuben kan det anbefales at gennemgå materialet hér på wiki-siden. Du kan også med fordel prøve at bygge din egen kube i Tabular Editor. Dette kan give en god indsigt i hvordan CHRU_HRKube er bygget op.
Brugerstyring og roller
Når man arbejder på en kube, er det vigtigt at man ved hvem der kan tilgå den. I dokumentationen af kuben er brugerstyring beskrevet. Her er det beskrevet hvordan vi benytter Row-Level Security (RLS) til at implementere brugerstyring på kuben. Ofte ønsker man dog først at lade folk tilgå en kube når den er færdigudviklet og klar til brug. Man kan se hvem der har adgang til en given kube ved tilgå kuben gennem SQL Server Management Studio (SSMS):
-
Åben SSMS og forbind til den ønskede kube. Højreklik herefter på en af rollerne og vælg “Properties”
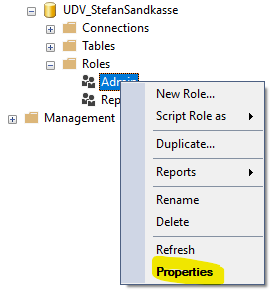
-
Under “Memebership” kan du se hvem der har fået tildelt den givne rolle. Ofte ønsker vi kun at folk internt i Data og Rapportering skal kunne tilgå kuber som stadig er under udvikling. Når sikkerhed og brugerstyrring er testet igennem, kan man tildele eksterne folk i regionen rollen “ReportReader”.
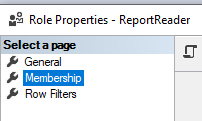
I Tabular Editor kan man implementere brugerstyrring og RLS. Man skal dog være opmærksom på at alle som kan tilgå kuben også kan tilgå alle measures gennem DAX-Studio. Så man skal ikke skrive personfølsomme oplysninger ind i de measures som ligger i kuben.
Dokumentation og versionsstyring af kuben
Når man laver ændringer i kuben er det vigtigt at dokumentere sit arbejde. Dels skal man sørge for at komme descriptions på alle measures, tabeller og kolonner. Men man skal også huske at opdatere dokumentationen på vores Wiki-side, så den ikke bliver uddateret. Dette er beskrevet i afsnittet om dokumentering.
Herudover benytter vi GitHub til versionsstyring af vores kuber. På denne måde kan vi let arbejde parallelt på den samme kube, og merge vores ændringer sammen. Hvis man laver ændringer i en kube, eller vil lave en ny kube, er det vigtigt at man benytter versionsstyring fra starten. Man kan læse mere om dette under versionsstyring.
Nedenfor er det beskrevet hvordan vi navngiver og opbygger vores kuber. Ved at følge disse konventioner, sikrer vi os at kubens opbygning er konsistent på tværs af temaer og emner.
Tabeller og relationer
Intro til tabellerne
I grove træk falder al data i kuben indenfor kategorierne
| Grunddata | Temaespecifik data | Hjælpetabeller | Infotabeller |
- Med grunddata menes den data, som er fællesmængde på tværs af temaer, uanset om der beregnes på sygefravær, ferieafholdelse eller andet. I grunddata indgår:
- Stamdata er personaledata, organisations-, stillings- og lønarthieraki, tidstabel mm.
- Brugerstyring er data om personales brugerroller, som er bestemmende for hvilke data, brugere af vores produkter må se. Det er essentielt at forstå, hvordan brugerstyring er implementeret for at sikre, at denne også virker på tilføjelser i kuben.
- Temaspecifik data anvendes specifikt til beregning af fx sygefravær, ferieafholdelse eller personalesammensætning.
Derudover findes en række øvrige tabeller, herunder:
- Hjælpetabeller er tally- og slicer-tabeller. Disse bruges til definering af intervaller (fx aldersintervaller), grupperings-, sorterings- og filtreringsmuligheder
- Info er data som fx dato på dataleverancer og servicemeddelelser til brugere af dashboard om nye opdateringer eller tilføjelser
Navngivning af tabeller
- Tabeller i kuben navngives på måden [tabeltype]+[_]+[Formål]+[BeskrivendeNavn] som fx v_DimAnsættelse, hvor
- Tabeltype angiver hvilken kilde tabellen bygger på, alle vores tabeller bygger på Views og indledes med v_
- Formål angiver tabellens funktion, og kan være Dim, Fact, Security, Info, Slicer, eller Tally.
- Beskrivende navn er entydig(e) og letforståelig(e) substantiv(er). Dette navne skal gerne være identisk med navnet på det view som tabellen bygger på. Sammensatte ord skrives i camelCase (StortBegyndelsesbogstav).
- Kolonnenavne skal være entydige og letforståelige substantiver, og navngives på følgende måde:
- Ligesom for tabelnavn skal kolonnenavnene være identiske med dem som er i det view som tabellen bygger på.
- Der benyttes camelCase
- Den primære nøgle i dimensionstabeller navngives ID, den fremmednøgle navngives [Beskrivende navn på dimensionstabel] + [ID]. Dette kan fx ses i tabellen v_DimExitSurveyRespondent som har en primærnøgle ‘v_DimExitSurveyRespondent’[ID] og en relation til ‘v_FactExitSurvey’[ExitSurveyRespondentID]. Det er vigtigt at huske at navngive disse kolonner korrekt, ellers kan datamodellen hurtigt blive uoverskuelig, og det kan være svært at få overblik over relationer.
Der er et par andre ting som man skal være opmærksomme på når man opretter tabeller i kuben:
- Undgå så vidt muligt datatransformation i Tabular Editor. Det giver bedre overblik at have samlet i views. Dvs. at datatypen, kolonnenavne, tabelnavn osv. skal være identisk med dem som er i det view tabellen bygger på.
- Husk at udfylde feltet med description Tabular Editor, både for tabellen og kolonnerne. Dette er også beskrevet i afsnittet om dokumentering.
- Sørg også for at formateringen af kolonnen er korrekt, så tal bliver vist med tusindtalsseparator og det ønskede antal decimaler.
- Man kan også udfylde feltet med Sort by Column. På denne måde kan man fx styre rækkefølgen spørgsmålstekster bliver vist i, når man laver figurer i PowerBI.
- Sørg også for at Securiry Filtering Behavior er sat til BothDirections i relationen mellem to tabeller, hvis man benytter en dobbeltvejs-relation. Ellers vil RLS ikke fungere korrekt, selvom der også kan være problemer med RLS, selv når man har indstillet Securiry Filtering Behavior korrekt.
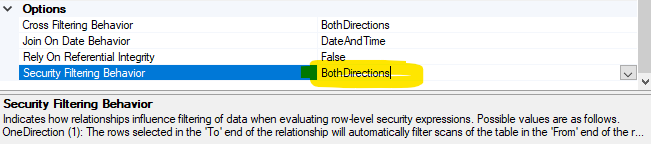
Measures
Intro til measures
Via measures implementeres vores standardiserede beregningsmetoder. De er grupperet temavis. I gruppen _Diverse indgår beregninger på stamdata og dette kan være et godt sted at starte med at skabe overblik over kuben. Foruden indblik i de mere centrale tabeller vil du hér se eksempler på, hvordan viden om stamdata er essentielt for at kunne definere fx hvilken personalegruppe, der skal indgå i en given beregning, hvordan dette kan variere fra tema til tema, hvordan antallet af personer, der indgår i en beregning, er afgørende for, om et resultat nødvendigvis skal anonymiseres mm.
Andre measures, som er lokaliseret i mapperne, _Farver og _Tekster, bruges til kontrol af layout på dashboards, Farvetemaer, dynamiske akselængder og tekstetiketter, meddelelser, kolonnebredder mm.
Navngivning af measures
Measures navngives efter formen [tema - beskrivende og letforståelig tekst] som fx [Fravær - vægtede fuldtidsfraværsdage]. De grupperes i temaspecifikke mapper, dog kan enkelte basis-measures placeres i mappen Diverse, hvis de bruges på tværs af temaer (som fx [Antal fuldtidsansatte] og [FilterSlicer]).
Husk også at udfylde feltet med description Tabular Editor. Dette er også beskrevet i afsnittet om dokumentering. Feltet med formatering af measuret skal også være udfyldt korrekt, så tal fx bliver vist med tusindtalsseparator.
[*] Ikke påbegyndt,
[†] Udarbejdes,
[§] Valideres