Sygefravær
Fravær er bredt defineret ved lønarterne i v_DimLønartFravær[L1Code]. Der filtreres globalt på fanen ud fra kriterierne v_DimAnsættelse[Ansat]=J, v_DimAnsættelse[Månedslønnet]=J og v_DimLønartFravær[L1Name]=’Fravær’. Som udgangspunkt vises altså alle lederens månedslønnede medarbejdere med en aktuel—eller historisk—ansættelse med statuskode 0, 1 eller 3, hvis denne i opgørelsesperioden har registreret fravær i en af førnævnte lønarter.
Fravær opgøres overordnet på én af to måder. Measure, [Fravær – antal arbejdsdage], summerer v_FactFravær[Arbejdsdage]. Med arbejdsdag forstås hér en fraværsdag opgjort relativt til planlagt tid, \(\frac{\text{fraværstimer}}{\text{planlagt arbejdstid}}\).
I modsætning hertil vises fravær også som løbende gennemsnit—over korte eller længere perioder—af antal fuldtidsfraværsdage relativt til den, på opgørelsestidspunktet, gennemsnitlige beskæftigelsesdecimal.
En fuldtidsfraværsdag er andelen af fraværstimer på en dag af en standard 7,4 timers arbejdsdag. Beskæftigelsesdecimal oversættes direkte til årsværk. ”Fuldtidsfraværsdage pr. årsværk” bruges som normaliseret og vægtet enhed og muliggør sammenlignelig på tværs af afdelinger, uanset at disse har forskellig sammensætning af fuld- og deltidsansatte samt varierende komposition i vagtlag.
Har bruger adgang til medarbejdere på tværs af organisationsstruktur, kan der filtreres herpå, ligesom der kan filtreres på tværs af stillingshieraki.
Foruden brug af grunddata er oprettet views og tabeller til brug i beregninger under dette tema. Se Resume af tabeller.
Lederdashboard
I dashboardet udstilles data på enkeltmedarbejderniveau tiltænkt ledere. Bruger får her overblik over udvalgte parametre om de medarbejdere, denne i forvejen har adgang til via PersonaleWeb. Se brugerstyring.
Beregninger
I figur Antal sygefraværsdage de seneste 12 mdr. udregnes på individniveau, [Fravær – antal arbejdsdage på tværs af org]. Measure ophæver relationen v_DimAnsættelse[OrganisationsID]➔DimOrganisation[ID] til fordel for relationen v_DimAnsættelse[NuværendeOrganisationsID]➔_DimOrganisation[ID] og beregner _[Fravær – antal arbejdsdage].
,CASE
WHEN [Start] >= CONVERT(date, GETDATE()) THEN OrganisationsID
ELSE
(SELECT OrganisationsID
FROM DM_FL_HR.DimAnsættelse sub
WHERE 1 = 1
AND sub.Tjnr = src.Tjnr
AND CONVERT(date, GETDATE()) BETWEEN sub.[Start] AND sub.Slut
)
END AS NuværendeOrganisationID
Dette, i kombination med filtret specifikt på denne figur, [Ansat på afdeling, nuværende afd]=1, gør, at bruger også ser data fra evt. tidligere ansættelser—på samme tjenestenummer!
[Ansat på afdeling, nuværende afd] =
--Er afhængig af den tilsvarende relation under "Relationships".
CALCULATE ( [Ansat på afdeling],
USERELATIONSHIP ( 'v_DimAnsættelse'[NuværendeOrganisationID], v_DimOrganisation[ID] )
)
hvor
[Ansat på afdeling] =
VAR RelevantPersonID = MAX ( 'v_DimAnsættelse'[PersonID] )
VAR RelevantePersoner = FILTER ( v_DimPerson, [ID] = RelevantPersonID )
VAR AnsatPaaAfdeling = IF ( COUNTROWS ( RelevantePersoner ) + 0 > 0, 1, 0 )
RETURN
AnsatPaaAfdeling
Endeligt filtreres på v_DimAnsættelse[AnsatDagsDato]=’J’, hvorfor kun personer med an aktiv ansættelse dd. vises—men altså også historiske asnsættelser, hvis tjenstenummer er bevaret.
Inaktiv relation mellem v_DimAnsættelse[NuværendeOrganisationID] og v_DimOrganisation[ID] anvendes her til at beregne fravær på individniveau (tjenestenummer). v_DimAnsættelse[NuværendeOrganisationID] viser, på alle tidligere ansættelser med samme tjenestenummer, hvor personen aktuelt er ansat dags dato. Har en medarbejder flere ansættelser på tværs af organisation, og har bruger også adgang til data herfra, vises medarbejderens totale fravær.
Via bogmærket, Fravær pr. type, ses samme beregning (akkumulkeret) i figuren Antal fraværsdage de seneste 12 mdr. fordelt på type, hvor filterkontekst på fraværstype (v_DimLønartFravær[L1Name]) er ophævet. Bruger kan til- og fravælge underkategorier via filter med standardindstillingen {”Sygefravær”, ”$56 fravær”, ”Arbejdsskade”, ”Graviditetsgener” }.
Igen filtreres på figuren med kriterierne, [Ansat på afdelingen, nuværende afdeling]=1 og v_DimAnsættelse[AnsatDagsDato]=J, hvorfor alle ansættelser med samme tjenestenummer på aktuelt ansatte medregnes.
Læs: Inspiration til measuret [Fravær – antal i fraværsinterval Ikke anonymiseret]
Daxpatterns.com \ Dynamic segmentation
I Sygefravær de seneste 12 mdr. fordelt på intervaller beregnes igen relative fraværsdage \(\frac{\text{fraværstimer}}{\text{planlagt arbejdstid}}\) på individniveau. [Fravær – antal i fraværsintervaller Ikke anonymiseret] beregner [Fravær – antal arbejdsdage på tværs af org] i kontekst af tally-tabellen, v_TallyFraværsintervaller[Interval.]. Intervaller inkluderer øvre grænseværdier. Igen filtreres på figuren med kriterierne, [Ansat på afdelingen, nuværende afdeling]=1 og v_DimAnsættelse[AnsatDagsDato]=J, hvorfor alle ansættelser med samme tjenestenummer på aktuelt ansatte dags dato medregnes.
Tally-tabeller er i vores fulde kontrol, hvorfor vi let kan konfigurere i intervalgrænser og -antal.
Læs: Inspiration til measuret [Fravær – vægtede fuldtidsfraværsdage gnsnit 12 mdr Ikke anonymiseret]
Sqlbi.com \ Rolling 12 Months Average in DAX
TIl beregning af ‘Gns. løbende sygefravær opgjort over seneste 12 mdr.’ anvendes to measures, [Fravær – vægtede fuldtidsfraværsdage gnsnit 12 mdr Ikke anonymiseret] og [Fravær – Benchmark regionen 12 mdr.]. Førstnævnte udregner
(1) for hver d. 1. i måneden i foregående 12 måneder den løbende gennemssnitssum af beskæftigelsesdecimaler på aktuelle ansættelser—også selvom de ikke er ansatte længere—,
...fra [Fravær – vægtede fuldtidsfraværsdage gnsnit 12 mdr Ikke anonymiseret])
VAR DenFoerste = FILTER ( Period, DAY ( [Dato] ) = 1 )
VAR AntalDageIPerioden = COUNTROWS ( DenFoerste )
VAR AntalFuldtidsdage = CALCULATE ( SUM ( 'v_FactFravær'[Fuldtidsdage] ), Period )
VAR PeriodMedBeskdec =
GENERATE (
DenFoerste,
VAR AktuelDato = [Dato]
VAR BeskSumPaaDagen =
CALCULATE (
SUM ( 'v_DimAnsættelse'[Beskdec] ),
'v_DimAnsættelse'[Ansat] = "J",
'v_DimAnsættelse'[Start] <= AktuelDato, AktuelDato <= 'v_DimAnsættelse'[Slut]
)
RETURN ROW ( "BeskSum", BeskSumPaaDagen )
)
VAR BeskSumPerioden = SUMX ( PeriodMedBeskdec, [BeskSum] )
VAR GennemsnitBesksum = DIVIDE( BeskSumPerioden, AntalDageIPerioden, 0)
...
og (2) månedlig sum af fuldtidsfraværsdage indeværende måned, v_FactFravær[Fuldtidsdage]. Endeligt (3) andel af fuldtidsfraværsdage af den gennemsnitlige beskæftigelsessum.
...fra [Fravær – vægtede fuldtidsfraværsdage gnsnit 12 mdr Ikke anonymiseret])
VAR GnsnitFuldtidsdage = DIVIDE ( AntalFuldtidsdage, GennemsnitBesksum, 0 )
RETURN GnsnitFuldtidsdage
...
(4) Denne er vist pr. måned med Kurven ’Aktuel visning’. På figuren filtreres v_DimTidDato[OffsetMaaned]=[-12;-1].
v_FactFravær[Fuldtidsdage] er antallet af fraværstimer på en dag relativt til en 7,4 timers arbejdsdag. Dette, i kombination med en gennemsnitssum af beskæftigelsesdecimaler, bruges til at normalisere beregning af fravær til ”antal fuldtidsfraværsdage pr. årsværk”. Enheden muliggør sammenligning af fravær på tværs af afdelinger, uanset at disse har forskellig sammensætning af fuld- og deltidsansatte samt varierende komposition i vagtlag.
(5) I samme figur er desuden, foruden regionens måltal for samme værdi, også benchmarking mod regionsgennemsnit af fuldtidsfraværsdage.
[Fravær - benchmark regionen 12 mdr] =
-- Measuret anvendes til benchmarkberegning af sygefraværet i hele regionen, idet organisatorisk filtrering undtages.
CALCULATE (
[Fravær - vægtede fuldtidsfraværsdage gnsnit 12 mdr],
ALL ( v_DimOrganisation )
)
Via bogmærket, ‘Sygefravær pr. måned’, ses fuldtidsfraværsdage over tid, hvormed sæsonvariation er tideligere.
I Gns. sygefravær de seneste 12 mdr. fordelt på afdelinger bennchmarkes fuldtidsfraværsdage mod regionens måltal og internt på tværs af afdelinger(er) (hvis bruger har adgang til flere).
[Fravær - Benchmark] =
VAR BeskSum = SUM ( 'v_FactAggFravær'[MaskeretBeskSum12Mdr] )
VAR FravSum = SUM ( 'v_FactAggFravær'[MaskeretFravSum12Mdr] )
RETURN DIVIDE ( FravSum, BeskSum, 0 )
Strategisk dashboard
I dashboard udstilles aggregeret data om fravær på organisations- og stillingsniveau. Bruger får her overblik over organisationer, som denne i forvejen har adgang til via PersonaleWeb. Se brugerstyring.
Fælles for alle beregninger er implementering af anonymitetsgrænsen. Hvor beregninger baseres på løbende nedslagsdatoer (som i [Fravær – vægtede fuldtidsfraværsdage gnsnit 12 mdr]) kontrolleres, at antal inkluderede individer på nedslagsdatoer er tilstrækkeligt. Hvis ikke udelades resultat på nedslagsdato. Hvor kun aktuelt ansatte dags dato indgår i beregning sikres, at_antal aktuelt ansatte dags dato er tilstrækkeligt.
Anonymitetsgrænsen indbygges i nogle measures for at forhindre identifikation af enkeltindivider.
Fanespecifikt filter, v_DimStilling[Hovedstillingsgruppe], fravælger grupperne ’Ansat uden løn’, ’Budgetteknik’, ’Politikere/tjm’, ’Samling’ og ’Ukendt’. v_DimLønartFravær[L1Name]=”Sygefravær” fjerner øvrige fraværstyper.
Beregninger
I alle figurerne [Udvikling i sygefravær [..]] samt Sygefravær de seneste 12 mdr fordelt på virksomheder udregnes det vægtede fuldtidsfraværsgennemsnit, [Fravær – vægtede fuldtidsfraværsdage gnsnit 12 mdr].
I Udvikling i sygefravær (12 mdr.) fordelt på hovedstillingsgrupper ses seneste 3 års løbende gennemsnit opgjort sidste dage i respektive år (via filter på v_SlicerNedslagsdatoer). Med input fra slicer kan bruger vælge nedslagsdato og dermed ændre filterkontekst for measure, [Fravær – vægtede fuldtidsfraværsdage gnsnit 12 mdr Benchmark]. Valgt nedslagsdato er bestemmende for, fra hvilken dato dette measure regner 12 måner bagud. Altså en dynamisk størrelse til benchmarking af aktuelt fravær med tidligere perioder.
Læs: Inspiration til measuret [Fravær – antal i fraværsinterval Ikke anonymiseret]
Daxpatterns.com \ Dynamic segmentation
I figurerne 5 og 6 beregnes igen relative fraværsdage (fraværstimer af planlagt tid), [Fravær – antal arbejdsdage på tværs af org]. I figur 5 bruges dette i [Fravær – antal i fraværsinterval] til beregning af antal personer i perioden—og på tværs af organisation—med antal fraværsdage indenfor definerede intervaller. Measure er designet til at indgå i kontekst af tally-tabellen, v_TallyFraværsintervaller[Interval]. Intervaller inkluderer øvre grænseværdier.
I figur 6 relativt fravær i [Fravær – antal under regionalt niveau] og i kontekst af v_TallyFraværMaaltal til gruppering af antal personer over og under regionens måltal.
Sygefravær
Datamodel
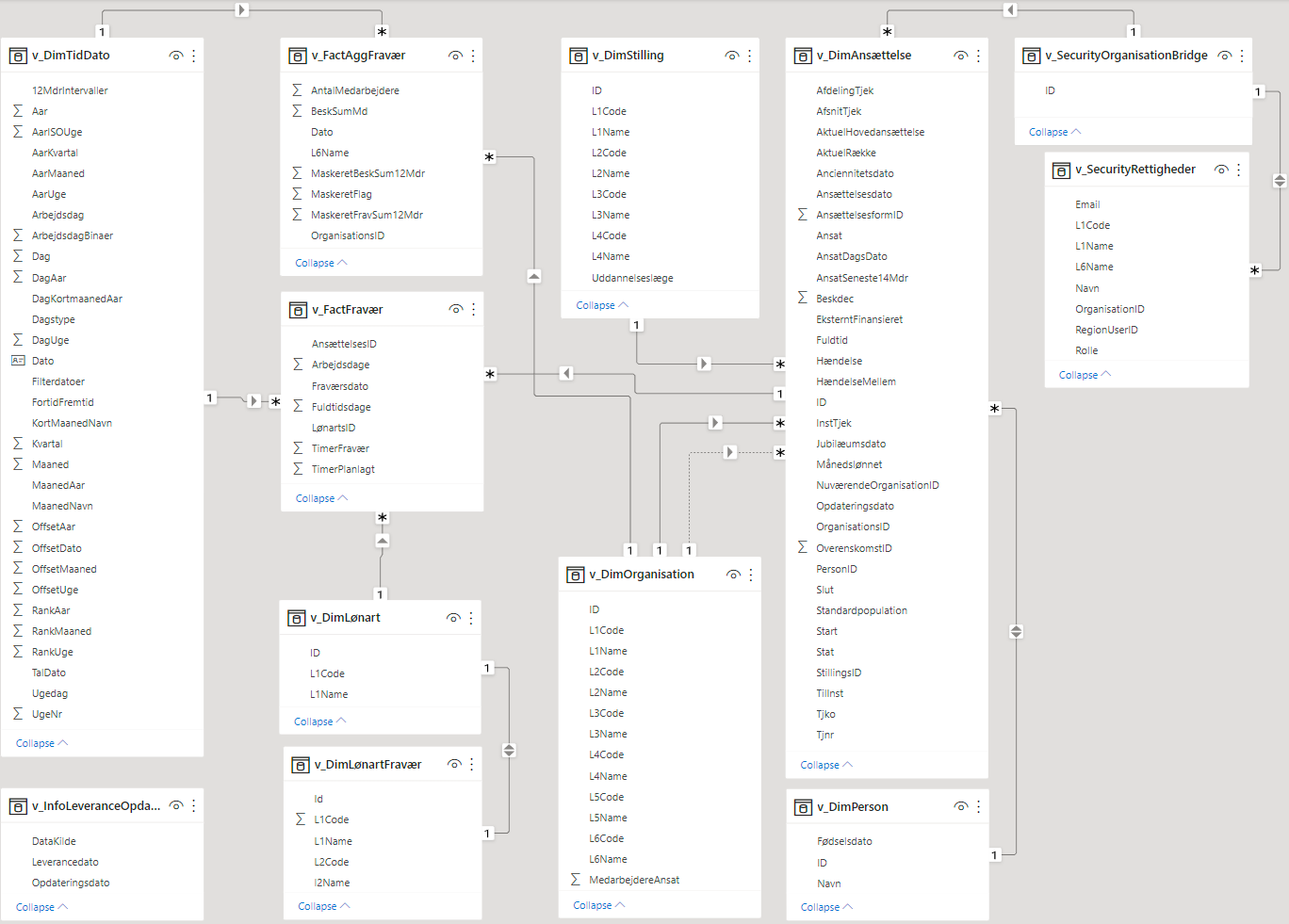
Resume af tabeller
v_DimLønartFravær
| View | Opdateres | Baseret på |
|---|---|---|
| [chru_cube].[v_DimLønartFravær] | Dagligt | [DM_FL_HR].[DimLønart] |
Subset af v_DimLønart med samme primærnøgle, ID. Indeholder kun lønarter relateret til fravær. Tabellen er i to niveuer. ’L1Code’ og ’L1Name’ er hard-codet kategorisering af visse lønarter i 3 fraværstyper; ’Sygefravær’, ’Barn syg’ og ’Andet’. ’L2Code’ er 3-cifret lønartkode—svt. ’L1Code’ i v_DimLønart—og ’L2Name’ er hard-codet undergruppering af fraværstyper.
,case
when l1code in(510, 771, 772, 775,760) then 'Øvrigt fravær'
when l1code in(520) then 'Omsorgsdag'
when l1code in(522,525) then '§56 fravær'
when l1code in(524,590) then 'Arbejdsskade'
when l1code in(790,526) then 'Sygefravær'
when L1Code in(780,527) then 'Graviditetsgener'
when l1code in(570,575,576,770) then 'Barsel og adoption'
when l1code in(680,950) then 'Kursus'
when l1code in(774) then 'Seniortimer'
when l1code in(910,929) then 'Barn syg'
end as l2Name
Vær opmærksom på, at gruppering på L2-niveau ikke er identisk er med SD’s LOENARTTXT
ØVELSE - FRAVÆRSTYPER 
I CHRU_HRKube anvendes i tabellen v_DimLønartFravær en anden gruppering af fraværstyper (L2Name), end den gruppering SD bruger (LOENARTTXT).
- Gør rede for ligheder og forskelle.
- Hvad er grunden til, at der i CHRU_HRKube anvendes en anden gruppering?
Se løsningsforslag.
v_FactFravær
| View | Opdateres | Baseret på |
|---|---|---|
| [chru_cube].[v_FActFravær] | Månedligt | [DM_FL_HR].[FactFravær] |
Ikke-indekseret tabel baseret på [DM_FL_HR].[FactFravær]. Kolonnerne ’AnsættelsesID’, ’Fraværsdato’, ’LønartsID’, ’TimerFravær’ og ’TimerPlanlagt’ er tilsvarende kolonnerne i SD’s [SD].[SD_FRAVDAG], ’AnsaettelsesID’, ’FRVDATO’, ’FRVAARSAG’, ’FRVTIM’ og ’PLANTIM’ . I chru_cube beregnes desuden kolonnerne ’Arbejdsdage’ som andelen af fraværstimer ud af planlagte timer og ’Fuldtidsdage’ som andelen af fraværstimer ud af 7,4t/dag. Fraværsdage på dage uden planlagte timer medregnes ikke.
ØVELSE - FRAVÆR
- Beregn sektionens fravær (fraværsdage og fuldtidsdage) i de seneste 12 hele måneder fordelt på enheder
- Sammenlign med HR Lederdashboarder
Se løsningsforslag.
v_FactAggFravær
| View | Opdateres | Baseret på |
|---|---|---|
| [chru_cube].[v_FactAggFravær] | Månedligt | [DM_FL_HR].[FactFraværAfsnit] |
| [chru_cube].[v_DimOrganisation] |
Ikke-indekseret tabel baseret på [DM_FL_HR].[FactFraværAfsnit]. Tabellen aggregerer fravær pr. måned pr. afdeling med opgørelses(’Dato’) hver d. 1. i en måned. ’OrganisationsID’ er F-nøgle til v_DimOrganisation, og L6Name henviser til afsnit i samme. ’AntalMedarbejdere’ er aktuelt ansatte på afsnittet opgjort på dagen, ’BeskSumMd’ er summen af beskæftigelsesdecimaler udgjort af aktuelt ansatte. ’MaskeretFlag’ har tidligere været brugt til indikation af få ansatte mhp. anonymisering—har i dag ingen funktion. ’MaskeretBeskSum12Mdr’ og ’MaskeretFavSum12Mdr’ er månedligt gennemsnit af hhv. beskæftigelsesdecimaler og fraværsdage i seneste år.
v_TallyFraværsintervaller
| View | Opdateres |
|---|---|
| [chru_cube].[v_TallyFraværsintervaller] | Dagligt / efter behov |
Tabel med dagsintervaller i intervaller af 5 dage. ’Intervaller’ er en tekststreng til beskrivelse af intervallet, fx ’5 til 10 dage’. ’ValueLow’ og ’ValueHigh’ er hhv. ned og øvre grænse (inkluderende—i measures defineres inklusionskriterier nærmere) af intervallet. ’Sortering’ er en numerisk værdi svt. rækkefølgen på intervallerne. Denne bruges til at nummerere tekstværdien i ’Interval’, så disse placeres i ønsket, sorteret rækkefølge på figurer og tabeller i Power BI.
v_TallyFraværMaaltal
| View | Opdateres |
|---|---|
| [chru_cube].[v_TallyFraværMaaltal] | Dagligt / efter behov |
Tabel med regionens måltal for fravær. To rækker beskrivende hhv. under og over måltallet fx ’>11.7 dg./år’. Kolonnerne ’ValueLow’ og ’ValueHigh’ er ned og øvre grænse (inkluderende) af intervallet. ’Sortering’ er en numerisk værdi svt. rækkefølgen på intervallerne. Denne bruges til at nummerere tekstværdien i ’Interval’, så disse placeres i ønsket, sorteret rækkefølge på figurer og tabeller i Power BI.
v_SlicerNedslagsdatoer
| View | Opdateres | Baseret på |
|---|---|---|
| [chru_cube].[v_SlicerNedslagsdatoer] | Dagligt / efter behov | [DM_FL_HR].[DimDato] |
’Dato’ med udvalgte nedslagsdatoer i intervallet fra dags dato og tre år bagud. ’DagKortmaanedAar’ med dato i formatet ”dd. mmm. yyyy”. Kolonnen ’Filterdatoer’ er tekst til nærmere beskrivelse af datoen; kan fx være ”I dag”, ”Den 1. i denne måned” eller ”Den 1. i tidligere måneder”. Bruges bl.a. til at simplificere i measures, hvor fx ansættelsedecimal evalueres for hver d. 1. i måneden.
[*] Ikke påbegyndt,
[†] Udarbejdes,
[§] Valideres